Learning Systems Architecture
Reliable Learning Systems Under Real-World Constraints
My work asks the question: how do we build learning systems that remain reliable when the world is messy?
Across physiological sensing, textile-based interaction, and naturalistic behavioral modeling, I design representations and system architectures that remain stable despite signals that are sparse, physically deformable, and highly variable across users and conditions, rather than increasing hardware complexity.
These systems demonstrate that robust inference is possible even with sparse sensing configuration, provided that models capture invariant temporal structures rather than relying on raw magnitude or high channel counts. The unifying principle of my work is reliability under constraint, across users, environments, and deployment conditions, with classification tasks also serving as probes of representation stability rather than only end goals.
What this page demonstrates:
- Minimal sensing with stable representations
- Cross-subject generalization without calibration
- Deployment-aware temporal modeling
- Robustness under deformation, drift, and real-world interference
General-Purpose Signal Infrastructure (BioHCI)
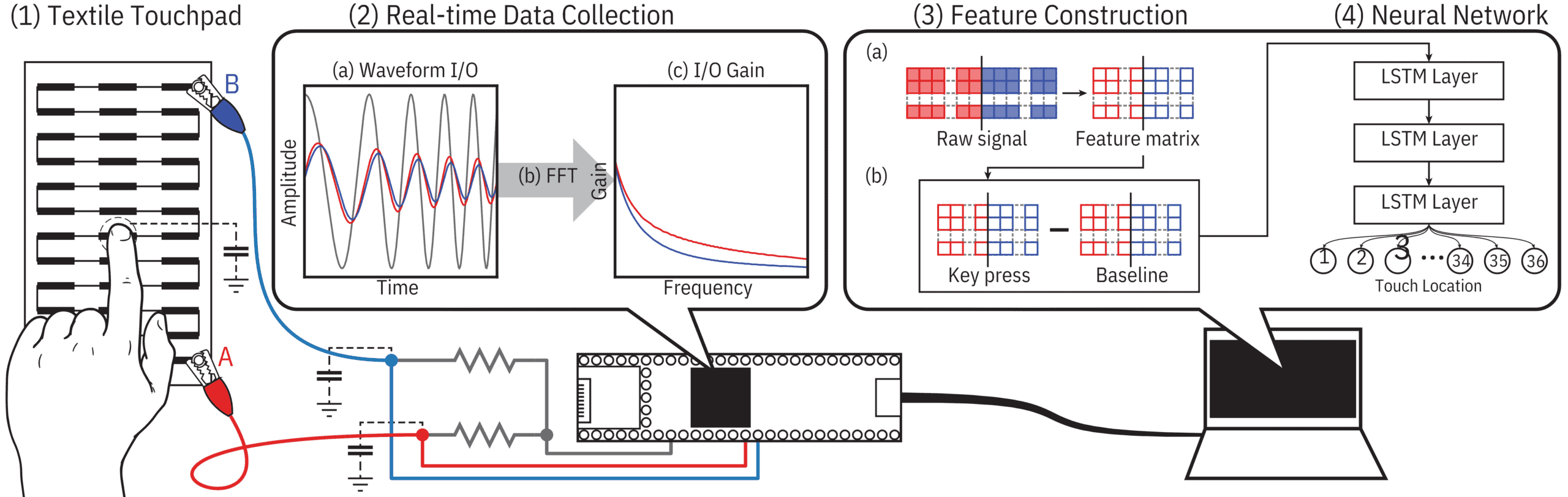
To support this work, I developed BioHCI, a 10,000+ line modular time-series learning framework that powers multiple real-world learning problems across sensing modalities. BioHCI evolved from my early fNIRS-based physiological modeling work through capacitive touch sensing pipelines into a unified architecture for structured human-generated signals. The framework integrates signal ingestion, representation construction, model abstraction, and evaluation into a reproducible experimental pipeline designed for real-world variability rather than narrowly controlled benchmarks.
Its design emphasizes modular experimentation, hardware-aware learning, and generalization under constraint. New sensing substrates can be incorporated by adapting preprocessing and representation modules while preserving a shared experimental structure. Study-level configurations define dataset organization, segmentation strategy, feature construction, imbalance handling, fold setup, and model settings, enabling comparable experiments across users, tasks, and signal types.

System Architecture
BioHCI is organized as a layered framework for modeling structured human-generated signals under noisy, sparse, and heterogeneous conditions. The architecture separates signal processing, representation construction, and task logic to support reproducibility, cross-domain reuse, and robust evaluation under natural variation. A core design principle is subject-centered abstraction: data are organized around participant-level structure, enabling consistent cross-subject and within-subject evaluation across sensing modalities and applications.
This design was motivated in part by the fact that segmented windows, adjacent measurements, and repeated observations from the same subject are not independent samples. Organizing data at the subject level helps preserve valid evaluation boundaries during windowing and prevents leakage between training and test sets unless within-subject splitting is explicitly desired. This was one of the original motivations for developing a custom framework rather than relying on a generic pipeline.
The framework is organized into three conceptual layers:
- Signal Layer: ingestion, filtering, normalization, segmentation, and frequency-domain characterization across textile, physiological, and behavioral inputs.
- Representation Layer: multi-scale feature extraction, temporal encoding, and modular interfaces for deterministic and stochastic models.
- Application Layer: task-specific modeling such as gesture recognition, localization, user identification, or behavioral inference.
This separation enforces clear system boundaries while enabling representation strategies to transfer across sensing substrates with different observability constraints and downstream goals. The same infrastructure supports both full offline experimentation and downstream inference workflows, producing comparable evaluation artifacts across studies.
Minimal Sensing as a Design Constraint
Many real-world learning systems cannot rely on dense, high-resolution sensing. Instead, they must operate under limited channel counts, lightweight substrates, low-profile hardware, and restricted observability, often by design rather than by accident. Across physiological sensing, textile interaction, and behavioral modeling, my work asks how much reliable inference can be recovered from such constrained signals without simply adding hardware complexity. Rather than compensating with denser instrumentation, I shift the burden into representation and modeling by:
- extracting stable structure from sparse signals,
- designing representations that remain robust to noise and drift,
- and building learning pipelines tailored to limited observability.
These domains differ in modality, but they share a common systems property: low-dimensional, temporally evolving signals that must support inference under substantial real-world variability. The following sections show how that constraint shaped the end-to-end design of the knitted capacitive sensing platform, from hardware configuration to representation learning, deployment, and robustness evaluation.
Hardware Limitations as System-Level Design Drivers
This work was conducted in close collaboration with Richard Vallett, who led circuit design and signal acquisition hardware development. My primary contributions were the modeling pipeline, post-acquisition signal processing, machine learning architecture, and experimental evaluation.
Real-world sensing systems rarely operate with dense instrumentation. Instead, they must balance sensing simplicity, signal richness, and computational feasibility. In this work, hardware limitations were treated as first-class architectural constraints rather than downstream implementation details. Two knitted sensor configurations illustrate this tradeoff clearly: a 2-electrode design optimized for minimal hardware and touch localization, and a 4-electrode design that modestly increases spatial observability to support more complex gesture recognition.
Both systems use a single conductive yarn sensing element with few external connections, but they differ in spatial observability, signal structure, and modeling requirements.
2-Electrode Optimization – Minimal Hardware Strategy
The first configuration used a single-wire touch surface constructed from conductive and non-conductive yarns arranged in a serpentine pattern across the textile substrate, with only two external connection points. This design prioritizes hardware simplicity and minimal wiring while preserving usable spatial information through representation and modeling. Key design choices included:
- Temporal windowing and statistical feature construction over multi-frequency gain values to enhance spatial signal separability
- LSTM-based discrete localization to infer touch location from limited observability
The objective was to maintain spatial inference capability despite severe sensing observability limits. This configuration is well-suited for touch location identification and simple gesture discrimination, but its non-uniform output between adjacent points and sparse sensing structure reduce contact continuity during complex gesture trajectories. This limitation directly motivated the 4-electrode design.
Signal Acquisition & Integration
- Embedded signal generation and acquisition via NXP Kinetis MK66 ARM Cortex-M4F 180 MHz microprocessor
- Frequency sweep across 96 frequencies between 2,000 Hz and 26,000 Hz for Bode characterization
- Two 16-bit ADCs sampling at 256k samples/second in 1024-point increments
- Hardware-in-the-loop operation at 125 Hz with USB data transfer to processing pipeline
4-Electrode Scaling – Complex Interaction Strategy
The non-uniformity and contact continuity limitations of the serpentine design motivated an architectural evolution: a planar conductive sensing surface with four external connection points, producing a more uniform resistance gradient in all directions. This modest increase in hardware complexity improved spatial observability without moving to a dense sensing grid, employing a richer spatial-temporal modeling strategy based on a CNN-LSTM architecture. Key design principles include:
- preserving a low-profile sensing footprint
- increasing structured spatial information through limited hardware scaling
- leveraging learned spatial–temporal representations rather than dense instrumentation
This configuration supports more complex gesture recognition while remaining within practical hardware constraints.
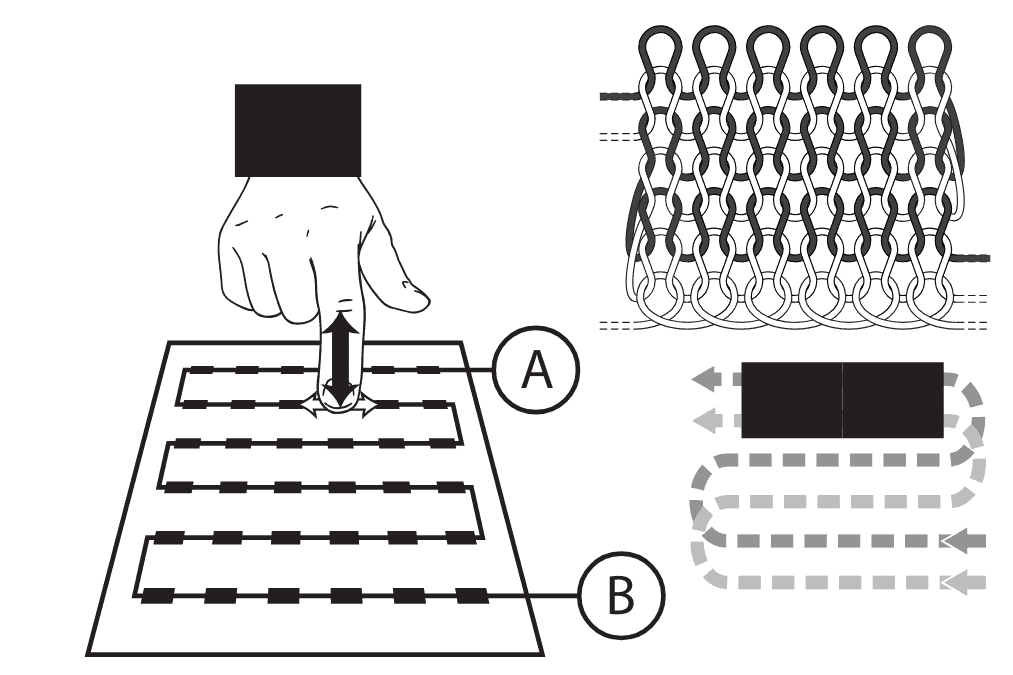
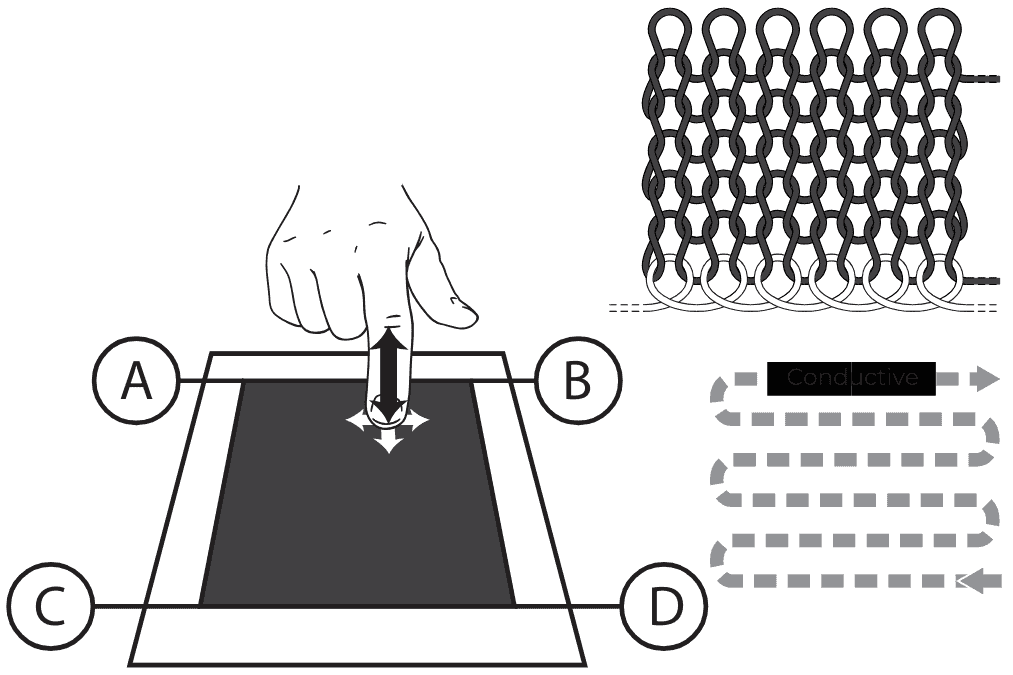
Diagrams of textile sensors. Left: A single-wire touchpad created using conductive and non-conductive yarns that serpentine across the textile surface. The points A and B connect to external sensing hardware. Right: Touchpad created as a planar conductive area with four connections points, A, B, C and D. From McDonald et al. (arXiv preprint 2023). Figure from Richard Vallett, Center for Functional Fabrics, Drexel University.
Signal Acquisition & Integration
- Signal generation and acquisition via bench equipment: Keysight 33622A arbitrary waveform generator and Keysight MSO-X-3024T oscilloscope
- 2 MHz sine wave input; gesture data captured at 250 frames per second over a 1-second window
- Each frame processed via Bode analysis to extract magnitude gain across four measurement channels, producing 250×4 input arrays
- Embedded acquisition is a planned next step; the current bench setup defines the present deployment boundary.
Signal Processing & Representation Pipeline
Real-world signals from physical substrates are noisy, multi-channel, and sensitive to environmental and hardware variability. BioHCI processes structured gain data through a configurable signal pipeline that separates preprocessing, representation construction, and downstream modeling. The exact operations vary by study, but the broader goal is consistent: transform sparse, unstable raw measurements into representations that preserve task-relevant structure while remaining usable across subjects and sensing conditions.
BioHCI receives preprocessed Bode gain files as input; signal acquisition and frequency-domain extraction are handled by the external hardware pipeline described above. Data remain organized at the subject level throughout preprocessing so that segmentation and representation construction preserve valid cross-subject evaluation boundaries. From there, preprocessing and representation steps are selected per study from a shared set of configurable operations.
Preprocessing
The preprocessing stage standardizes raw gain inputs before temporal modeling. Depending on the sensing substrate and study design, this stage includes:
- chunking and windowing into fixed-length temporal segments, with configurable size and overlap
- baseline subtraction to remove constant signal components and emphasize interaction-specific structure
- noise filtering through Butterworth or wavelet-based methods depending on substrate characteristics
Representation Construction
Representation strategy is selected based on signal complexity and modeling approach:
- Statistical feature construction: compact statistical summaries extracted over multi-frequency gain values within sliding temporal windows. This approach was used in the 2-electrode pipeline and in earlier physiological modeling work, where lightweight representations were important for stable inference under limited sensing and for deployment-conscious modeling.
- Wavelet-filtered direct model input: filtered multi-channel signals provided directly to temporal models after wavelet reconstruction. This approach was used in the 4-electrode gesture pipeline, where richer spatial-temporal structure made learned representations more effective than hand-crafted summaries.
- General-purpose representation modules: the framework also includes custom modules such as Mixed-Source Description (MSD) and Euclidean Levenshtein Distance (ELD), developed as part of this research for structured sequential signals. These are described in more detail on the Research page.
Imbalance Handling
Where appropriate, training distributions are adjusted through configurable within-subject oversampling. This supports more stable optimization under skewed class frequencies while preserving subject-level evaluation boundaries.
Temporal Modeling & Zero-Calibration Inference
On top of structured signal representations, I implemented temporal deep learning models for touch location identification and gesture recognition across both sensor configurations. Across both systems, classification accuracy serves not only as a performance metric but as a probe of representation quality, whether the constructed representations capture stable, generalizable structure rather than subject-specific or condition-specific patterns.
Modeling Architecture
2-Electrode System — Touch Location Identification
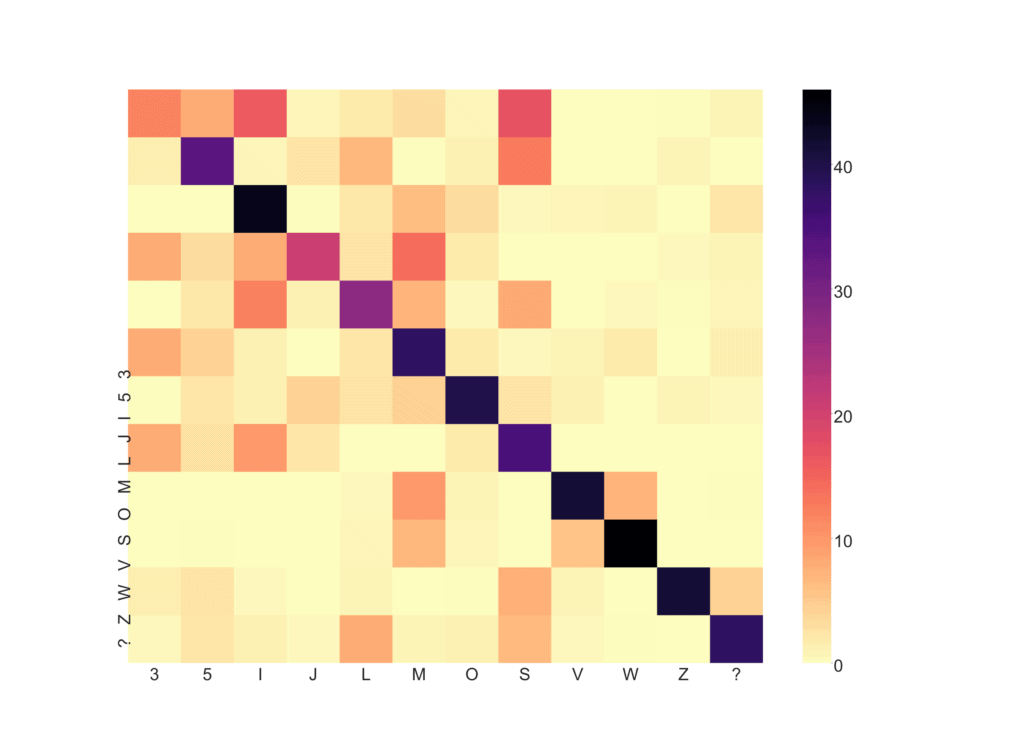
An LSTM-based architecture was trained to classify touch location across 36 buttons on the knitted touchpad. The model receives statistical features constructed over multi-frequency gain values as input: 92 frequency gains extracted via Bode analysis, processed into a 250×16 representation per key-press. The temporal architecture was chosen to preserve sequential dependencies across the key-press signal.
Two benchmarks confirm both design choices were necessary: using single-frequency raw input instead of multi-frequency features reduced accuracy to 25.3% (vs 58.3%), while replacing LSTM with a non-temporal MLP reduced accuracy to 46.3%, demonstrating that both multi-frequency feature construction and temporal modeling contributed independently to performance.
4-Electrode System — Gesture Recognition
For the 4-electrode system, I trained a CNN-LSTM architecture to classify 12 complex gesture classes, corresponding to a subset of English language characters. The CNN component captures local spatial structure across the four measurement channels, while the LSTM models temporal dependencies across the 250-frame gesture sequence.
An architectural benchmark confirms that this combination was necessary. The CNN-LSTM achieved 89.8% held-out evaluation accuracy, compared with 52.5% for a standalone LSTM trained on the same data, a 37-point gap, showing that spatial feature extraction across the four channels is essential for this task. Full benchmark analysis is described on the Research page.
Cross-Subject Generalization: Zero-Calibration Results
Both systems were evaluated under subject-independent conditions with no per-subject calibration. This was a deliberate design decision: calibration would be expected to increase accuracy, but requiring it makes multi-user interaction intrusive and limits real-world scalability. All subjects in held-out evaluation contributed zero data to training.
Across both systems, performance on completely unseen subjects matched or exceeded cross-validation accuracy, indicating robust zero-calibration generalization rather than overfitting to the training participants.
| System | Condition | Subjects | Accuracy | Chance |
| 2-Electrode | Cross-validation (10-fold) | 24 subjects | 58.3% | 2.78% |
| 2-Electrode | Held-out evaluation | 7 new subjects | 66.2% | 2.78% |
| 4-Electrode | Cross-validation (LOO) | 5 subjects | 78.6% | 8.3% |
| 4-Electrode | Held-out evaluation | 3 new subjects | 89.8% | 8.3% |
The improvement from cross-validation to held-out evaluation in both systems indicates model stability rather than subject memorization. For the 2-electrode system, 66.2% represents a 23x improvement over chance across 36 classes. For the 4-electrode system, 89.8% represents an 11x improvement over chance across 12 classes. The fact that this pattern appears in two different sensing architectures, on different datasets and tasks, strengthens the case that the modeling approach generalizes beyond any single experimental setup.
Deployment Architecture: Online & Offline Learning Pipelines
This work was produced in collaboration with Lev Saunders and Richard Vallett.
The gesture recognition system was developed with deployment feasibility as a design constraint rather than an afterthought. Model architecture, preprocessing structure, and execution flow were organized to support inference on embedded hardware with limited computational resources.
Training was performed offline on a multi-GPU Ubuntu workstation, after which the CNN-LSTM model was deployed to an NVIDIA Jetson Xavier NX to validate embedded inference capability. This demonstrated that the modeling and preprocessing pipeline could be separated cleanly from training and executed on resource-constrained GPU-enabled hardware.
Signal acquisition and preprocessing remained tied to bench equipment in the current system boundary, using a Keysight 33622A arbitrary waveform generator and oscilloscope. The deployed inference pathway operated on structured gesture windows stored as signal files. Before classification, baseline subtraction and waveform filtering were applied to normalize inputs and preserve representational stability under hardware variability.
The deployed system classified inputs into one of 12 gesture categories using the trained temporal model, with an average response time of 30 ms1, a practical latency for inference in a real-time system2. Separation was maintained between offline training and inference execution. The training pipeline handled data preprocessing and model optimization, while the deployed inference pathway operated independently on preprocessed inputs. This separation supports modularity, reproducibility, and a clear transition from experimental pipeline to deployable interaction system.
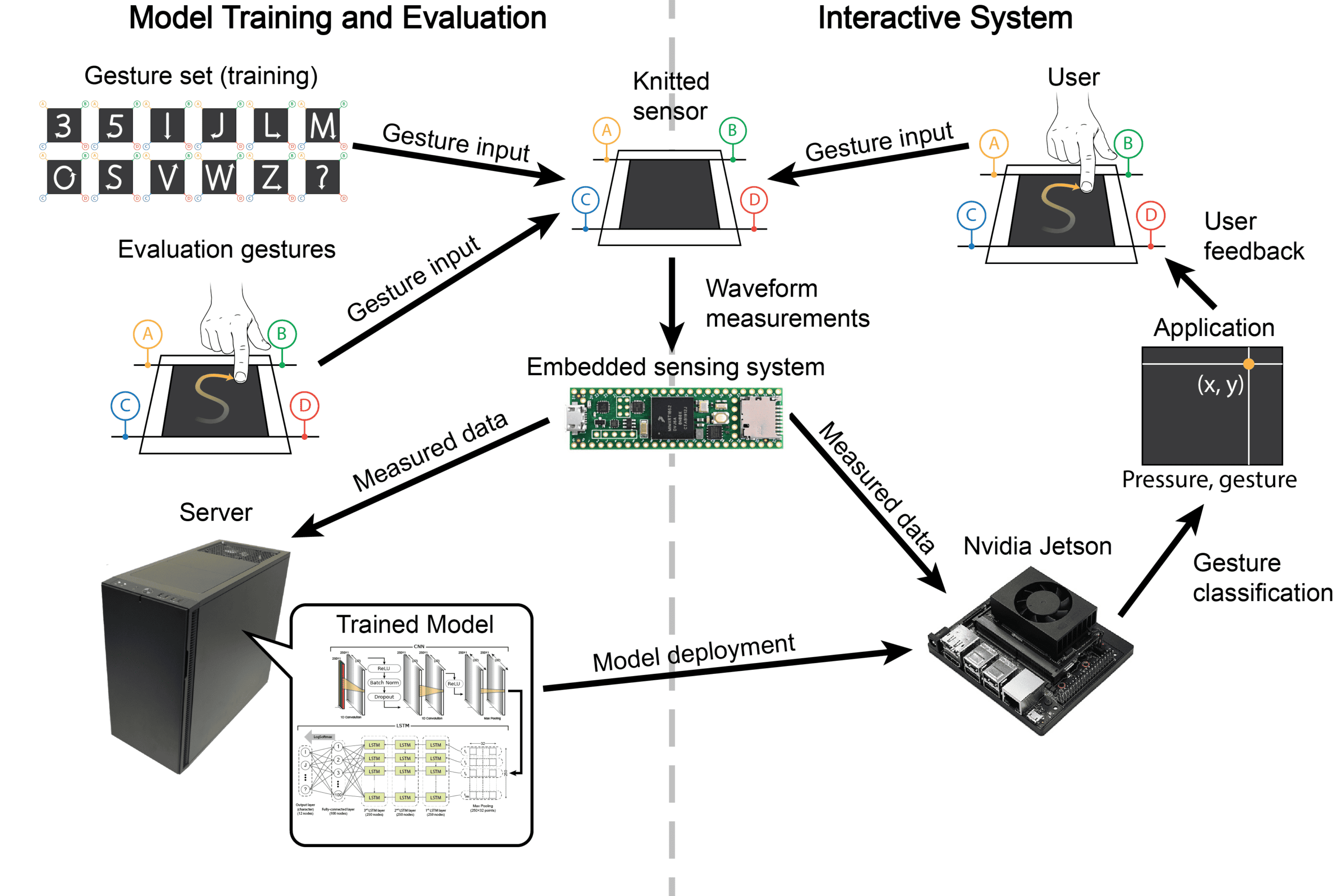
Although the current deployment operates on pre-segmented gesture windows, the architecture was intentionally structured to support future transition toward continuous streaming classification. Extending the system to real-time operation would require:
- Sustained signal acquisition and preprocessing on embedded hardware
- Online gesture-window segmentation upstream of the classifier, potentially using a new model to determine gesture boundaries
Importantly, the deployed CNN–LSTM inference pipeline demonstrated compatibility with the ARM + Volta GPU architecture of the Jetson platform, validating that structured temporal modeling can operate within compact edge environments. This deployment exercise reinforces a broader systems principle: modeling for complex interaction must account not only for representational quality, but also for limited instrumentation, modularity, and inference feasibility under realistic hardware conditions.
Real-World Robustness & System Resilience
This work was produced in collaboration with Richard Vallett.
Interactive textile systems operate under conditions that differ substantially from laboratory settings, including on-body deformation, mechanical stretching, laundering-induced drift, environmental electromagnetic interference, and incidental contact. Unless otherwise noted, all robustness conditions were evaluated zero-shot on trained models with no retraining: the same models trained under controlled laboratory settings were applied directly to each new condition.
On-Body Deployment: Physical Distribution Shift
When worn on the body, the sensor experiences curvature, non-uniform pressure, motion artifacts, and parasitic coupling effects that alter signal statistics relative to controlled bench-top recordings. Under these conditions, the 4-electrode gesture model maintained 58.0% accuracy compared with an 8.3% chance baseline, despite no on-body training data. For context, controlled evaluation achieved 89.8% accuracy in McDonald et al. (arXiv preprint 2023). This shows that the learned representations retain meaningful gesture structure under substantial physical distribution shift, even though confidence is reduced relative to the laboratory setting. Incorporating on-body samples during training would be expected to improve performance further, but even without adaptation the model remained well above chance.

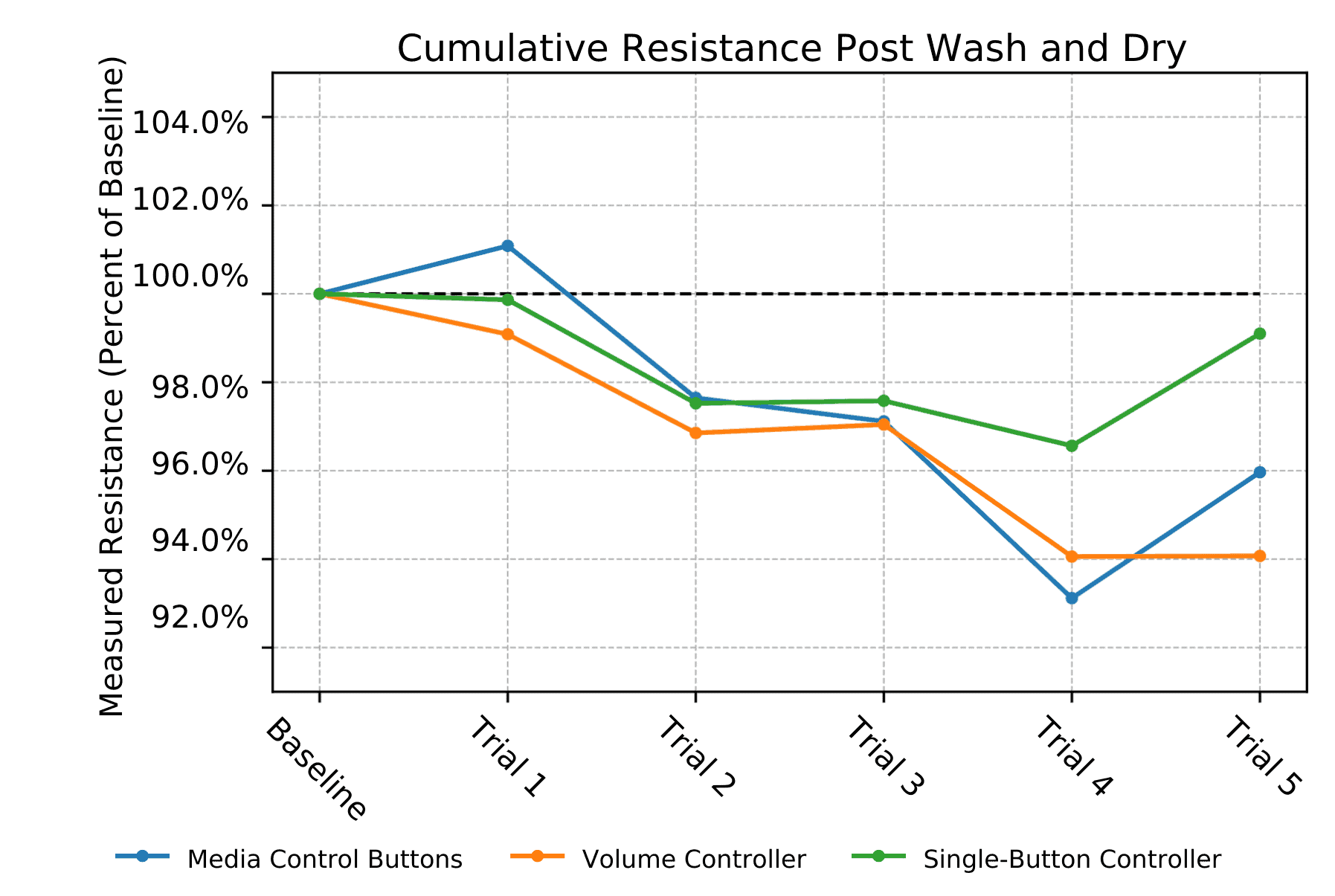
Structural Drift: Washing and Drying
Repeated laundering changes the electrical characteristics of conductive textile structures, but the observed drift remained bounded rather than catastrophic. In the 2-electrode sensor patterns, resistance stayed within 7% of baseline after five wash cycles (McDonald et al. (CHI 2022)). In the 4-electrode configuration, variation across connection pairs ranged from 1% to 31%, again indicating structured change rather than failure (McDonald et al. (arXiv 2023)). From a systems perspective, this means the challenge is not random noise but baseline drift: models should depend less on absolute magnitude and more on relative or structured signal properties. The sensing substrate remained functional across all cycles, supporting viability under everyday textile care, though the direct impact of laundering-induced drift on model accuracy remains an open evaluation question.

Stretching
Horizontal and vertical stretching modifies conductive pathway geometry, altering the resistance distribution between touch locations. Stretching was characterized at two levels: hardware behavior across sensor designs, and inference accuracy on a deployed model, using different experimental setups that should be read as complementary rather than directly comparable.
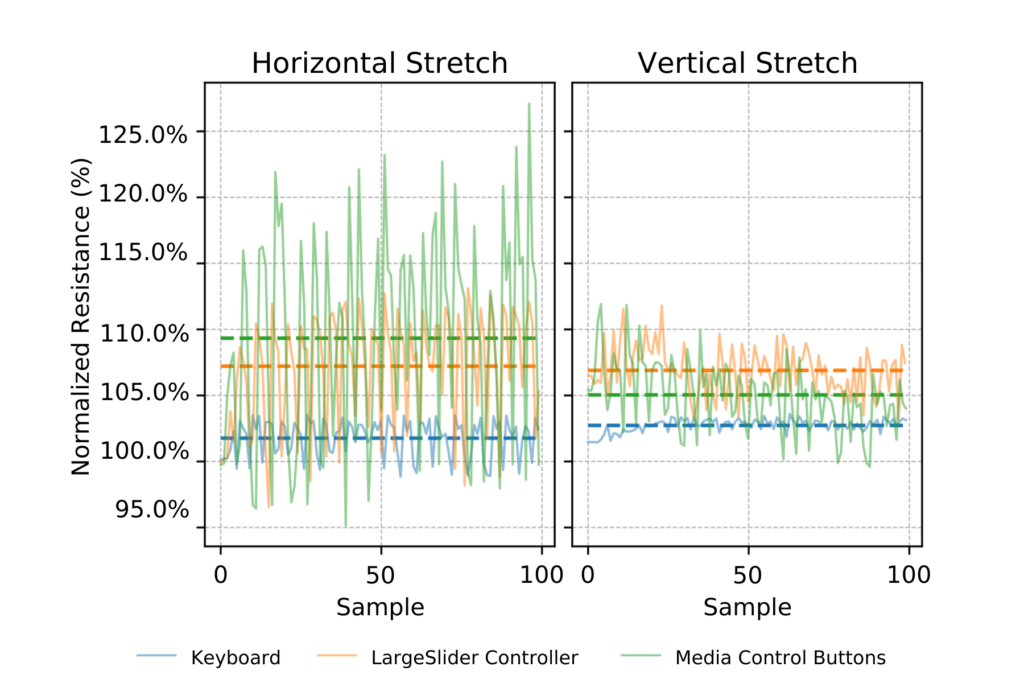
Hardware characterization: resistance under deformation
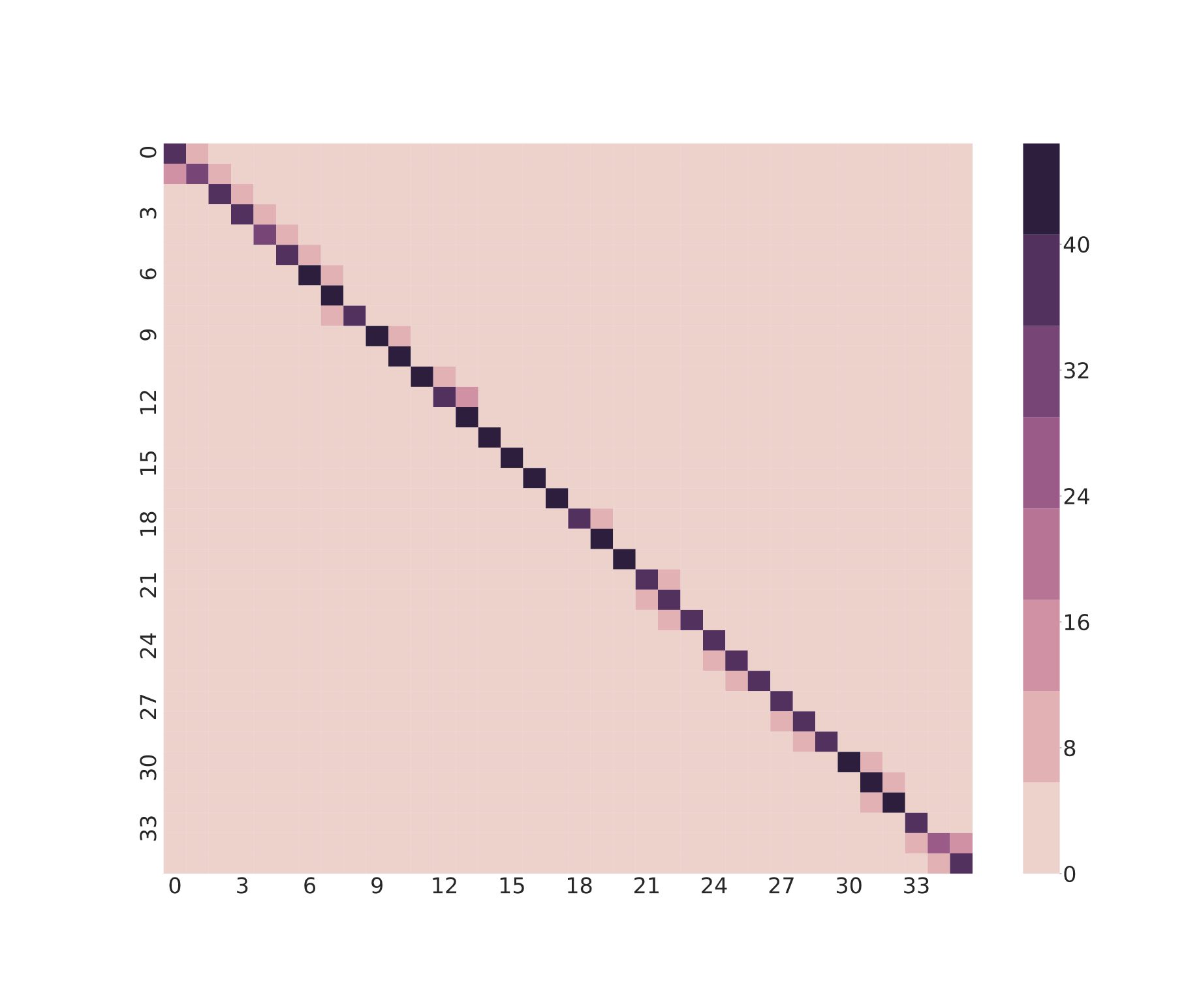
Horizontal and vertical stretching modifies conductive pathway geometry, altering the resistance distribution across the sensing surface. Three 2-electrode sensor designs were tested, the Keyboard, the Media Control Buttons, and the Slider Controlle, each with different conductive yarn routing patterns that produce different resistance distributions and localization strategies. The figure below shows resistance values across 100 consecutive stretch samples for each design, with the signal fluctuating during active stretch and partially recovering, producing structured rather than random variation. The degree of impact depends on the sensor’s localization strategy. The Slider Controller, which measures continuous change along the full length of the circuit, is more tolerant of resistance shifts than the Keyboard, which requires precise resistance separation between discrete button locations.

Inference under stretching: model accuracy
To evaluate the impact of stretching on the trained touch location identification model, data was collected from subjects interacting with the sensor while it was being actively stretched. This was evaluated zero-shot on the trained 2-electrode LSTM model with no retraining under stretching conditions. Accuracy dropped to 37.2% from the 58.3% cross-validation baseline, which is a significant degradation directly attributable to the resistance shifts characterized above, which alter the effective location of individual buttons and disrupt the spatial separability the model relies on. Training under stretching conditions would be expected to recover substantial accuracy. This result defines a clear boundary condition for deployment: the current model is not robust to significant mechanical deformation without retraining (McDonald et al. (IMWUT/UbiComp 2021)).
Electromagnetic Interference (EMI)
Conductive textile traces can act as long antennas and are susceptible to environmental electromagnetic interference. EMI introduces low-amplitude fluctuations and transient artifacts that distort the measured waveform. By capturing signal strength across multiple frequencies via Bode analysis the system retains separability between touch locations even under interference conditions. This is the most striking robustness result across all conditions tested: evaluated zero-shot under EMI from a fluorescent lamp at 12-18 inches, the model achieved 79.5% accuracy, exceeding the 58.3% cross-validation baseline and indicating no measurable degradation from electromagnetic interference (McDonald et al. IMWUT/UbiComp 2021).
Incidental Contact
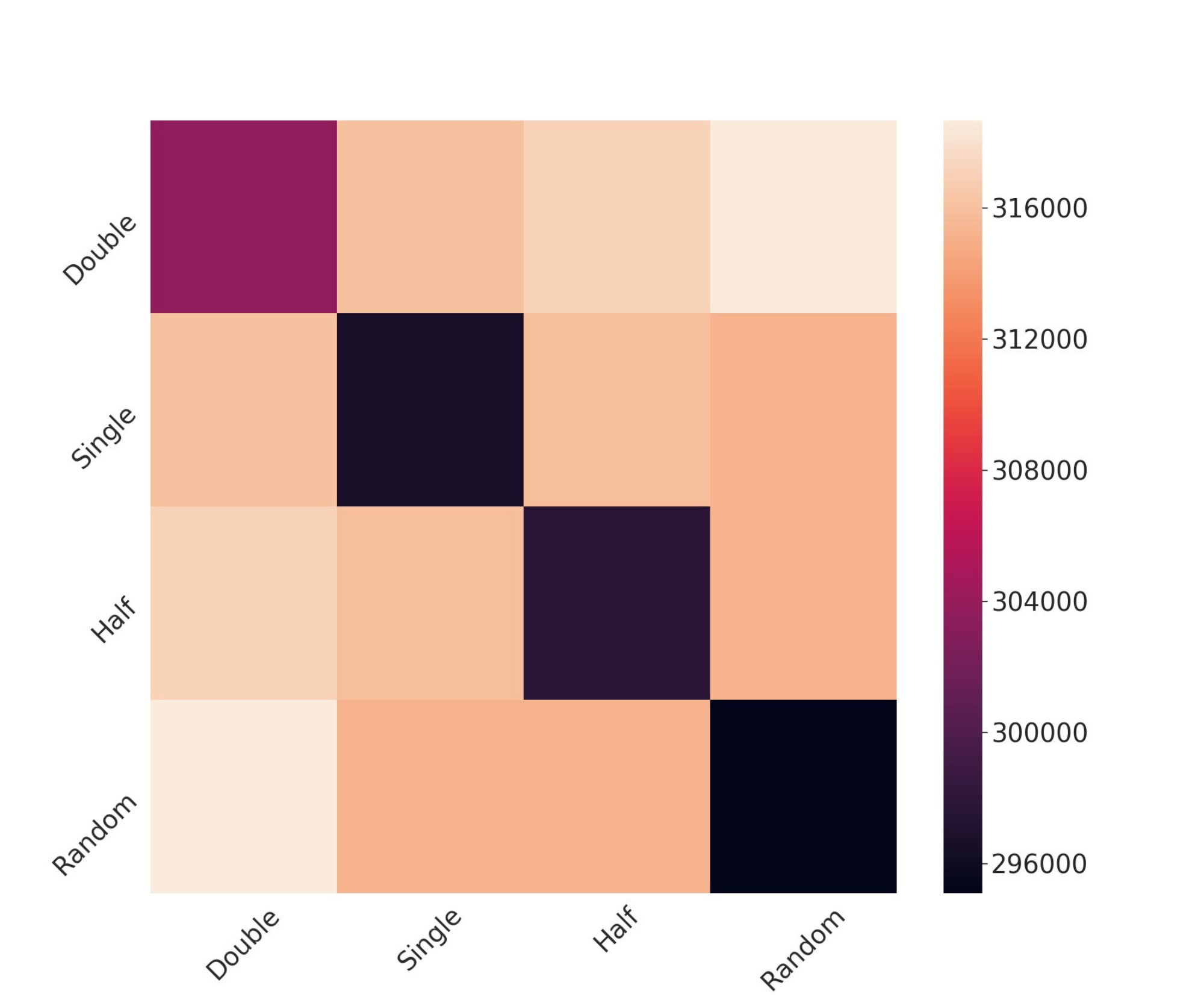
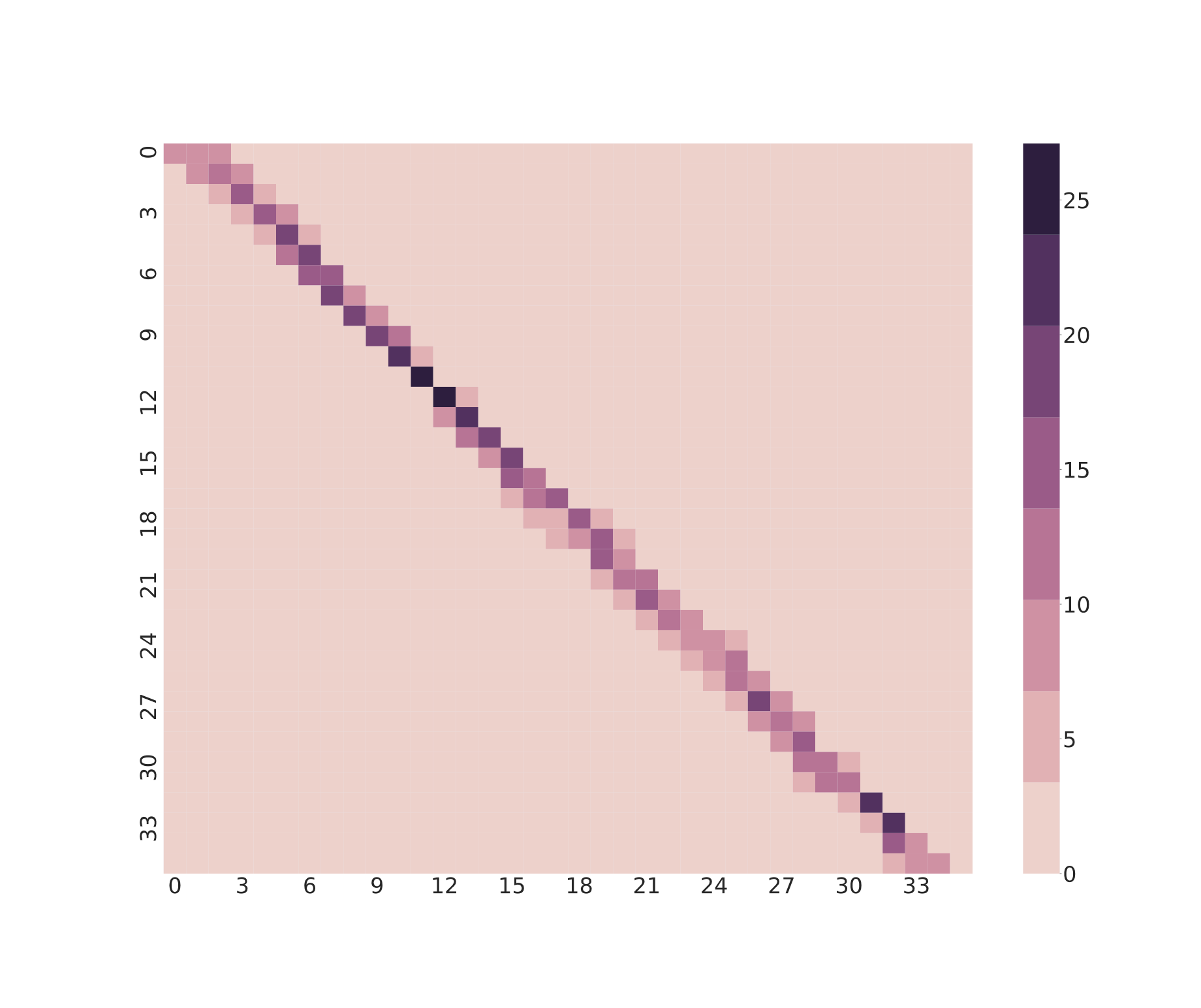
Everyday interaction includes accidental touch. Using ELD as a similarity metric across gesture samples from 12 participants, intentional gestures — full swipe, half swipe, double swipe — remained separable from incidental contact with strong statistical significance (f-statistic 231.81, p = 0.00).
The resulting similarity structure shows that intentional gestures cluster together while random contact forms a distinct class. This is important not only as a signal-processing result, but as a human-centered modeling one: practical interactive systems must distinguish deliberate interaction from unstructured perturbation.
Systems Perspective
Across these projects, the central systems challenge is not simply classification from sensor data, but designing representations and learning pipelines that remain useful under sparse sensing, physical variability, and limited hardware. The knitted sensing platform is one concrete instance of that broader problem: extracting stable structure from low-dimensional, temporally evolving signals while separating task-relevant information from nuisance variation introduced by users, substrates, and operating conditions.
What ties this work together is a consistent design philosophy: treat sensing constraints as part of the learning problem, enforce valid experimental boundaries during evaluation, and build representations that generalize beyond controlled settings. In practice, that means organizing data around subject-level structure, preserving cross-subject evaluation integrity, adapting modeling choices to observability limits, and testing performance under deformation, drift, interference, and other real deployment conditions.
Taken together, these components show how I design learning systems that remain reliable under constraint, from signal acquisition and representation construction through temporal modeling, deployment, and robustness evaluation. Although this page focuses on interactive textile sensing, the broader contribution is a systems approach to real-world machine learning for structured human-generated signals.
- The first trial takes 7.3 seconds due to bootstrap and cuDNN cache allocation. The 30ms statistic applies to subsequent trials. As per the paper, the first trial can be handled with a non-relevant warmup sample in real deployment. ↩︎
- For a fully-interactive system, the response time of the signal acquisition and processing controller would need to be added to that response time. ↩︎