Research
Representation Learning for Real-World Sequential Data
My research centers on a question that sits behind many prediction problems: what kind of representation preserves the structure that remains informative across users, contexts, and conditions? Across textile sensing, conversational behavior, and physiological time series, I study settings where observations are limited, temporally structured, and shaped by embodiment, interaction, and sensing constraints. Rather than treating prediction solely as an end goal, I also use it as a probe of representation quality — asking not just whether a model performs well, but whether the structure it has learned remains stable and meaningful when users, environments, and conditions change.
Core question
How can models recover reliable structure from sparse, noisy, human-generated signals without simply relying on denser instrumentation?
Research themes
Limited observability
A recurring theme in my work is learning from signals that provide only partial access to the underlying phenomenon: minimally wired textile sensors, conversational video, and compact physiological measurements. In these settings, performance depends on recovering stable structure from incomplete observations rather than assuming abundant instrumentation.
Temporal structure
Many of the signals I study are meaningful because of how they unfold over time: touch events, gesture trajectories, head-movement patterns in interaction, and physiological dynamics. My work therefore emphasizes sequential representations and temporal models rather than static summaries alone.
Generalization
I am especially interested in whether learned structure survives realistic variation: new users, new environments, physical deformation, natural social interaction, and distribution shift. This emphasis appears across my work in cross-subject evaluation, zero-calibration inference, robustness analysis, and deployment-aware modeling.
Knitted Sensors: Learning Human Intent from Minimal Hardware
Research agenda
My knitted-sensor research explores how computational modeling can enable digitally knitted textile substrates to function as a general interactive sensing platform: soft, low-profile sensor designs that recover human intent through touch and gesture and support downstream applications built on top of that inference.
Across this work, the central question was not simply whether a classifier could perform well, but how far representation learning and temporal modeling could extend the capabilities of minimally wired textile hardware while preserving manufacturability, robustness, and usability. Across four papers, that question became progressively harder and the modeling approach evolved accordingly: from invariant representation and sequence comparison for sparse touch signals in Vallett et al. (EICS 2020), to precise touch localization on a 36-button surface in McDonald et al. (IMWUT/UbiComp 2021), to complex multi-class gesture recognition on a more capable sensor configuration in McDonald et al. (arXiv 2023).
A formative study with 32 users conducted in McDonald et al. (CHI 2022) sits between the localization and gesture-recognition work as a grounding instrument for the broader platform agenda. It validated that agenda against real user requirements, identified gesture capability and physical durability as baseline expectations, and translated user-identified concerns into concrete technical research questions that the later gesture-recognition work addressed directly.


Digitally knitted capacitive sensors. Left: sensor design and construction. (a) Illustration of the layered structure formed by digital flatbed weft knitting with conductive carbon-coated nylon yarn and non-conductive polyester yarns. (b) Top layer of a completed sensor, with darker lines indicating touch areas. (c) Bottom layer of the completed sensor. (d) Serpentine conductive-yarn pathway formed by the knitting process. Right: real-time sensing controller connected to a knitted sensor through electrodes at the yarn endpoints. From McDonald et al. (IMWUT/UbiComp 2021). Figures by Richard Vallett, Center for Functional Fabrics, Drexel University.
Invariant representation and sequence comparison
A central technical theme in this work was designing representations and metrics that remain informative despite sparse hardware and signal variability. In Vallett et al. (EICS 2020), I developed Mixed-Source Description (MSD) as a sparse, SIFT-inspired representation for multi-channel signals that captures salient local invariances rather than relying on brittle raw sample-wise comparison. The goal was to preserve the parts of the signal most stable under timing variation, deformation, and local shape differences while producing a shorter, more discriminative representation.
The discriminative improvement is directly quantifiable. Evaluated with ELD (a custom sequence distance metric introduced below) on a 36-button touchpad dataset collected from 13 subjects, raw signal representations yielded an ANOVA f-statistic of 58.26 (p = 0.00) separating same-location from different-location key-presses. MSD raised that to 2,279.20 (p = 0.00), an approximately 39× increase in group separability, while also reducing conflation between nearby buttons. The heatmaps below make this visible: the diagonal sharpens and the off-diagonal structure clears substantially under MSD.
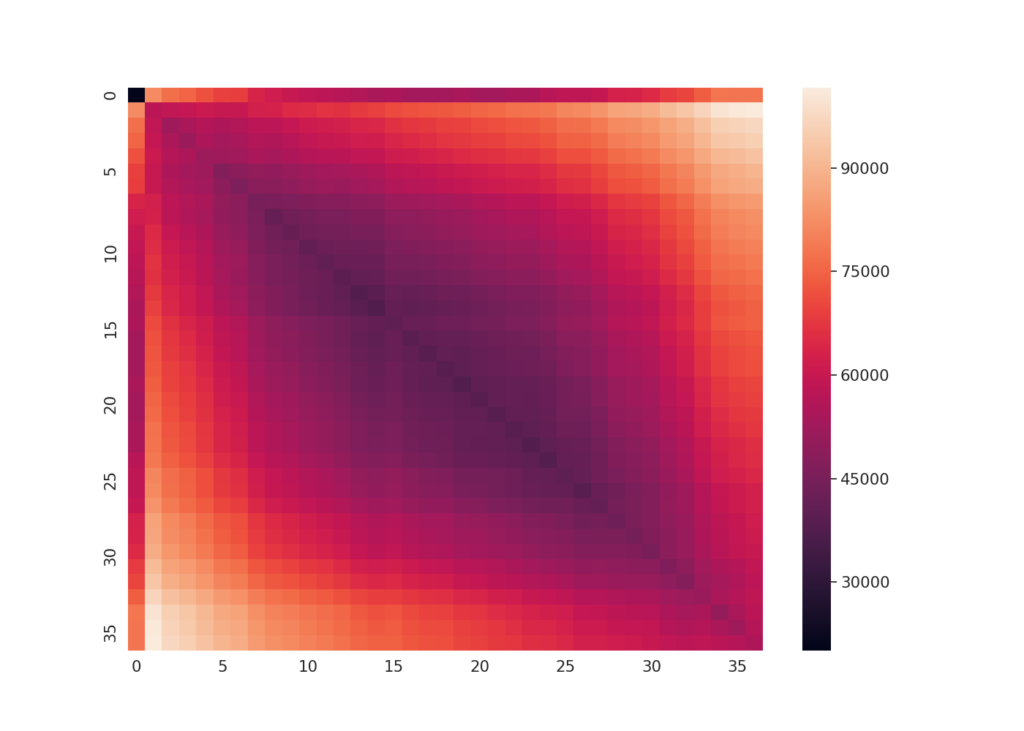
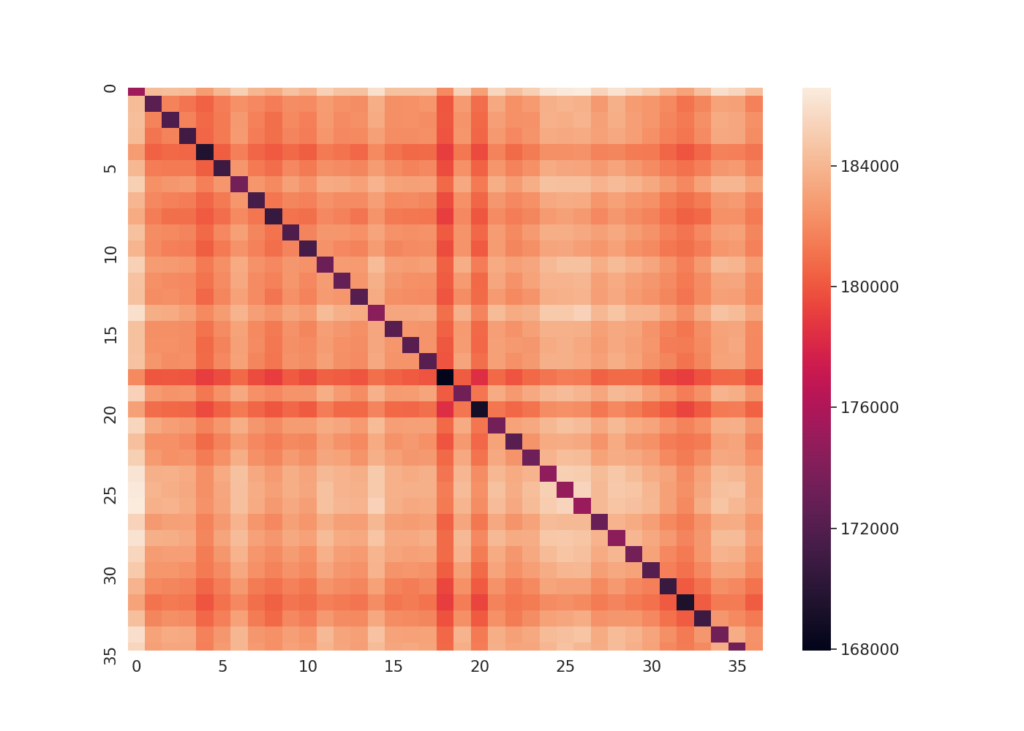
Pairwise touch-location distance matrices computed using ELD across 210 key-presses per button on a 36-button knitted touchpad (13 subjects). Each cell (i, j) represents the summed ELD between all key-presses at location i and location j; lower diagonal values indicate within-class similarity. Left: raw signal representation (f-statistic 58.26). Right: MSD representation (f-statistic 2,279.20). The sharper diagonal and cleaner off-diagonal structure under MSD reflect the approximately 39× increase in group separability reported in the text. From Vallett et al. (EICS 2020).
MSD’s sparsity also has an important computational consequence. Computing the full pairwise distance matrix for one subject’s data took approximately 17 hours under raw signal representation and approximately 20 minutes under MSD, a roughly 50× reduction in processing time on identical parallel hardware. This matters not only as an efficiency result, but as evidence that sparse representation is a meaningful design choice for any downstream analysis or deployment pipeline that must operate over variable-length sequences.
In the same work, I introduced Euclidean Levenshtein Distance (ELD) as a sequence metric that extends edit-distance logic to continuous multi-dimensional signals. Instead of treating sequence comparison as exact match versus mismatch, ELD computes Euclidean costs between temporally ordered descriptors, allowing flexible alignment while preserving sequential structure. This makes it better suited than fixed-length vector distances for human-generated signals whose timing naturally varies.
ELD was designed as a general-purpose metric applicable to any problem that requires measuring the minimum cost of converting one variable-length tensor sequence into another. Its generalizability is demonstrated by its reappearance in McDonald et al. (CHI 2022), where I used it to analyze similarity among swipe and accidental-contact samples on a different sensor configuration. This shows that the metric transfers across sensing substrates and interaction types rather than being tied to a single experiment.
Feature construction and temporal modeling for touch localization
This work was conducted in close collaboration with Richard Vallett, who led the real-time signal acquisition hardware, embedded sensing pipeline, and sensor design exploration. My primary contributions were the representation strategy, modeling architecture, experimental evaluation, and the analytical framework connecting sensing constraints to modeling decisions.
In McDonald et al. (IMWUT/UbiComp 2021), the work advanced on two fronts simultaneously: a real-time signal acquisition and processing system, and a classification model that could identify precise touch location on the knitted sensor without user-specific calibration. Vallett et al. (EICS 2020) had established invariant representation and variable-length sequence comparison but had not identified touch location directly and had processed all signals offline. Moving to a real-time embedded pipeline with swept-frequency Bode analysis across 96 frequencies, rather than the single input frequency used in the earlier work, provided a richer characterization of the signal at each time step and shaped every downstream modeling decision. Hardware and acquisition details are covered on the Systems page.
Representation strategy
The central contribution was constructing compact, stable features from the multi-frequency signal before temporal modeling rather than passing raw gain values directly to the model. At each of the 250 time steps in a key-press, I computed statistical summaries over the full frequency response of each electrode, capturing central tendency, spread, and linear trend in a form more stable than raw per-frequency magnitudes. Baseline subtraction removed constant ambient components, preserving only interaction-specific structure.
The resulting 250×16 representation per key-press is temporally ordered, which is precisely why an LSTM was the right modeling choice: the problem is not classifying a feature vector but recognizing how a press unfolds over time. Feature construction steps and LSTM architecture are detailed on the Systems page.
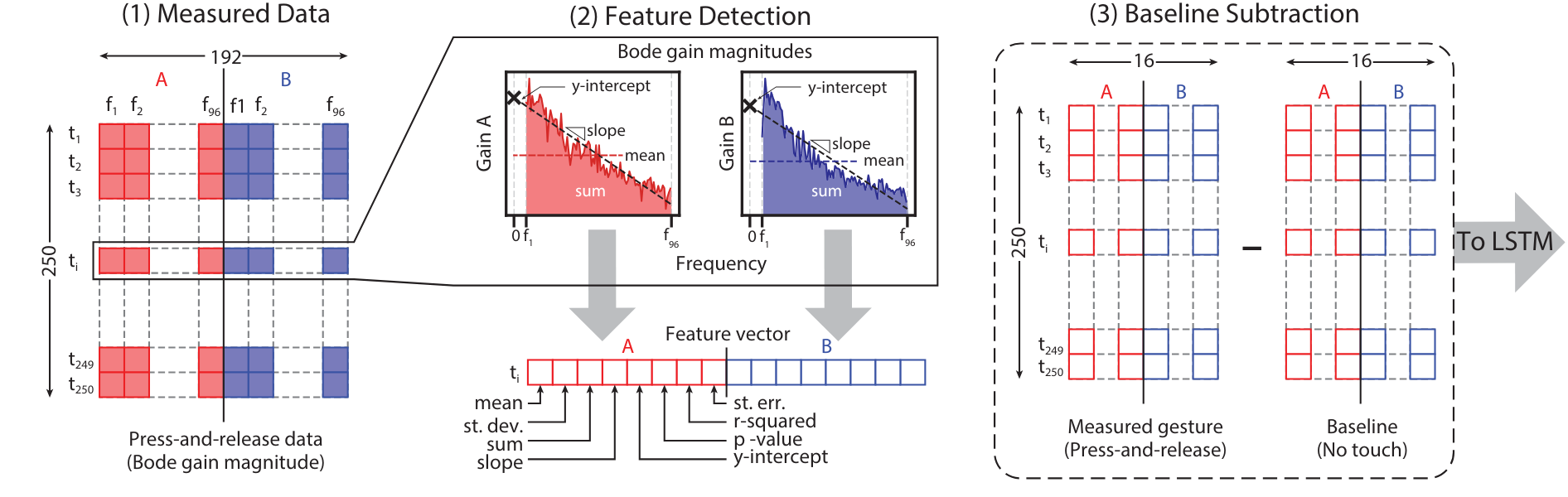
Feature construction over frequency gain values of signals from both electrodes: (1) the raw data is composed of 250 time instances and 96 frequency values per signal, for a total of 192; (2) statistical features are computed over the frequencies per time step; (3) baseline is subtracted from key-press data. From McDonald et al. (IMWUT/UbiComp 2021). Figure in collaboration with Richard Vallett, Center for Functional Fabrics, Drexel University.
Benchmark structure
The benchmark design was deliberate: each comparison isolates a specific modeling claim. Replacing multi-frequency features with single-frequency raw input dropped accuracy to 25.3%, testing whether swept-frequency feature construction added value. Replacing the LSTM with a non-temporal MLP dropped accuracy to 46.3%, testing whether temporal modeling added value independently. Both degradations were substantial, showing that feature construction and temporal modeling were each necessary rather than one compensating for the other. Full benchmark results are on the Systems page.
Zero-calibration design
All evaluations were conducted subject-independently, with no per-subject calibration. This was a deliberate design choice. Calibration would likely increase accuracy, but it also makes multi-user interaction intrusive and limits real-world scalability.
The three-study evaluation structure reflects that commitment. Study 1 established model performance through cross-validation across 24 subjects. Study 2 tested generalization on 7 entirely new subjects who contributed no data to training. Study 3 evaluated zero-shot robustness under EMI and stretching conditions using the same trained model. Structuring the evaluation this way made it possible to validate generalization and robustness separately rather than collapsing both into a single held-out test.
The system achieved 66% subject-independent accuracy on a 36-button touchpad with chance near 3%. Held-out evaluation exceeded cross-validation accuracy, indicating stable generalization rather than subject-specific overfitting.
Sensor design exploration
The paper also introduces multiple new sensor designs — game controllers, a piano keyboard, a volume slider, and media-control buttons — and compares their gain-separation profiles across different yarn-routing geometries. This establishes a principled relationship between textile design choices and sensing performance.
Designs with larger conductive areas and greater inter-touchpoint resistance produce more analytically separable signals. The 36-button touchpad used for all modeling experiments was deliberately the most difficult case among them, with low inter-button resistance and a dense serpentine layout that minimizes signal differences between adjacent locations. That choice was intentional: demonstrating the modeling approach on the most challenging design makes the results more broadly informative.
User Perspectives and Research-Driven Experimentation
In McDonald et al. (CHI 2022), I extended the research agenda in a direction that technical performance metrics alone cannot address: what users actually expect from this technology, what interaction capabilities it needs to support, and whether the physical substrate can withstand everyday use.
Formative study
I conducted a formative study consisting of 8 focus groups with 32 participants, analyzing the data through thematic analysis. Participants interacted with multiple sensor prototypes and application demonstrations — touchpads, sliders, a piano keyboard, game controllers, and a MIDI controller system — and were asked about their perceptions, desired applications, and hesitations.
Several analytically substantive themes emerged, including:
- Material framing: Participants understood the technology through its identity as fabric: texture, softness, robustness, portability, and low production cost. Those framings directly shaped which applications they found compelling and which user populations they imagined benefiting most.
- Application space: Users envisioned three broad classes of applications: familiar interfaces reimagined in fabric form, ambient integration into everyday environments, and body-proximate sensing for health, occupational, and assistive use.
- Design considerations: Participants valued unobtrusive appearance, cared about personal style and color variation enabled by the manufacturing process, and had specific views on size and thickness tradeoffs across contexts.
- System expectations: Participants expected hardware minimalism and connectivity with existing devices, reasoning about the sensor as a component within a broader system rather than a standalone novelty.
Most importantly, a distinct concerns cluster emerged around accuracy, safety, and everyday reliability. Participants repeatedly asked whether gestures beyond simple taps would be supported, whether the sensors could survive washing and stretching, and whether incidental contact during ordinary use would trigger false interactions. These were not abstract concerns; they identified concrete functional requirements without which adoption would be unlikely.
Together, the study produced 10 design guidelines for application designers working with this technology, addressing texture, comfort, scalability, target user groups, modularity, and communication of safety properties.
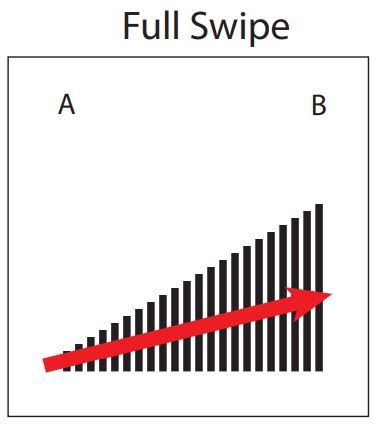

Four interaction classes for gesture-level signal separability evaluation. The first three — full swipe, half swipe, and double swipe — have similar but distinct trajectories, chosen to test whether overlapping motion primitives remain distinguishable at the signal level. The fourth, random contact, captures accidental touch during everyday use: participants simulated incidental contact without a prescribed trajectory. Its inclusion reflects a deliberate stance: separating intentional interaction from accidental perturbation is a human-centered inference problem, not merely a signal-processing problem. From McDonald et al. (CHI 2022). Figures by Richard Vallett, Center for Functional Fabrics, Drexel University.
Research questions generated
Two concerns from the study translated directly into follow-up experiments conducted within the same paper: whether closely related intentional gestures: swipe, half-swipe, and double swipe, could be distinguished from one another and from accidental contact, and whether the physical substrate remained stable under everyday use conditions including washing, drying, and stretching. Both experiments are covered in detail on the Systems page, and both were driven by specific user-identified requirements. In that sense, the formative study functioned as a research prioritization instrument, not just as contextual framing.
The next question was what it would take to recognize complex, multi-class gestures in a deployable system. That step required a more capable sensor design, a richer spatial-temporal architecture, and broader attention to deployment feasibility and physical robustness.
Spatial-temporal modeling for gesture recognition
In McDonald et al. (arXiv 2023), the research question shifted from localizing static touch events to recognizing complex continuous gestures. That transition required rethinking the sensor design, signal-processing strategy, and modeling architecture together. The 2-electrode serpentine configuration was insufficient for this task: its non-uniform resistance gradient and sparse touch areas fragmented continuous gesture trajectories, motivating a move to the 4-electrode planar design described on the Systems page.

Pathways of the collected gestures. Left: The knitted component of the sensor on which the gestures were performed; Right: All the gesture pathways that were collected and analysed. From McDonald et al. (arXiv 2023). Figures by Richard Vallett, Center for Functional Fabrics, Drexel University.
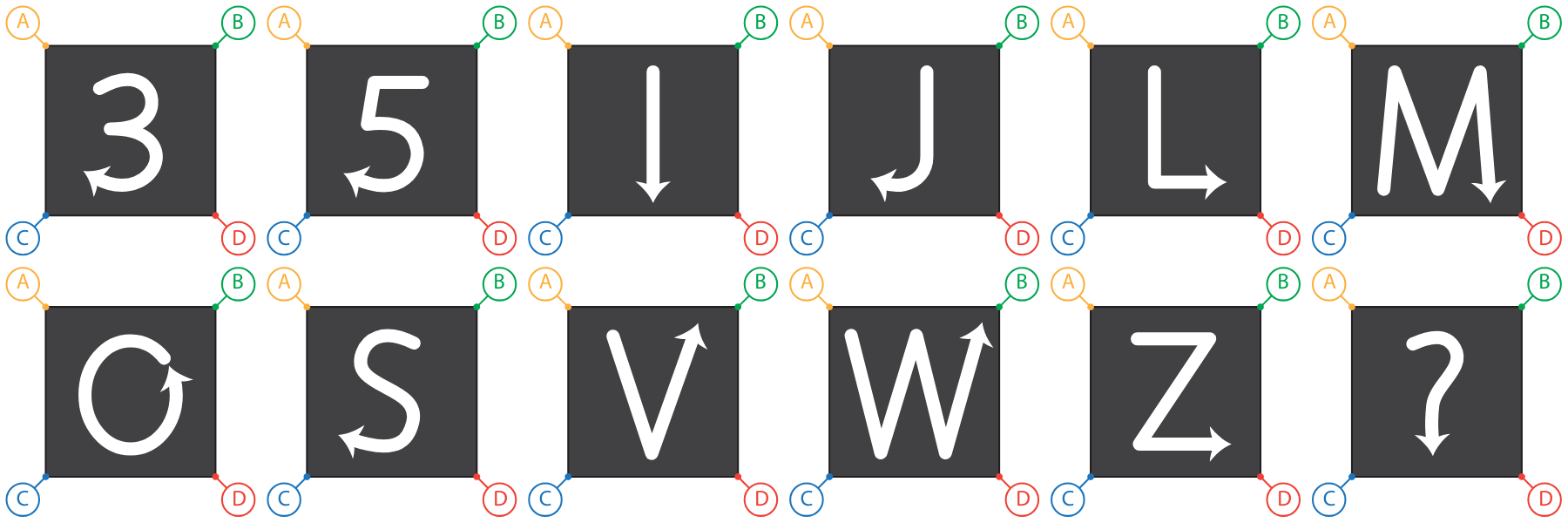
Gesture set
The 12 gesture classes — 3, 5, I, J, L, M, O, S, V, W, Z, and ? — were selected on principled criteria. Each can be performed as a single continuous motion with a distinct onset and offset; they vary deliberately in complexity from simple (I) to complex (?); and they include similar pairs such as S and 5 and V and W to test whether the system could discriminate gestures with substantially overlapping motion primitives.
The set was also designed as a first step toward a broader alphanumeric recognition system and, more generally, toward fabric-based communication interfaces, rather than as a convenient sample of gestures.
Signal processing and architecture
Rather than constructing hand-engineered statistical features as in the 2-electrode pipeline, the 4-electrode system passed baseline-subtracted, wavelet-filtered signals directly to the model. This shifted more of the representation burden from manual feature construction to learned spatial extraction.
That architectural choice follows from the signal structure itself. At each time step, the four-channel gain measurement contains meaningful spatial structure: the relative attenuation pattern across the four corner electrodes encodes where on the surface the gesture is occurring. A CNN is well suited to extracting that local spatial structure. Its translation-tolerant behavior helps capture consistent patterns across users who place their fingers slightly differently, while composing those local patterns into higher-level features without requiring them to be hand-specified.
The LSTM then operates on that learned spatial representation across the 250-frame gesture window, modeling how the pattern evolves over time: the trajectory, velocity, and directional changes that distinguish one gesture from another. Neither component alone is sufficient. Spatial extraction without temporal modeling cannot represent gesture trajectories, and temporal modeling without spatial extraction cannot recover the structured location information encoded in the four-channel signal. This is also what the benchmark results support; details are on the Systems page.
Results
The system achieved 89.8% held-out evaluation accuracy and 78.6% cross-validation accuracy across 12 gesture classes, both subject-independent and without per-subject calibration. The fact that held-out accuracy exceeded cross-validation accuracy is consistent with the generalization pattern observed in the 2-electrode system and supports the interpretation that the model learned stable structure rather than overfitting to training subjects.
System framing
The broader contribution of this work was moving toward an interactive system architecture: offline data collection and model training, deployment on compact embedded hardware, real-time classification, and application-layer interpretation. This required treating deployment feasibility, on-body robustness, and durability under repeated laundering as first-class research questions from the outset; those results are discussed on the Systems page.
The work therefore demonstrates a path from minimalistic textile hardware to a deployable gesture-recognizing interactive system, closing the loop between the application vision established in McDonald et al. (CHI 2022) and a functioning technical implementation.
Why this line of work matters
This research demonstrates a broader principle: interaction capacity in physically constrained systems depends on representation design and temporal modeling rather than dense instrumentation alone. Across this work, increasingly sophisticated interaction — from coarse touch discrimination, to precise localization, to complex gesture recognition — was achieved primarily through advances in representation and architecture, with hardware scaling playing a secondary and deliberate role.
McDonald et al. (CHI 2022) add something that purely technical work cannot: evidence that the design philosophy resonates with users, that the application space is broad and user-identified rather than researcher-assumed, and that everyday-use requirements such as durability, accidental-contact handling, and gesture capability can be translated into concrete technical research questions.
Taken together, these papers make a case that extends beyond textile sensing. Sparse, noisy, physically constrained signals can support rich human-computer interaction when the modeling approach is designed for the constraints rather than in spite of them.
The knitted-sensor work developed representations and models for recovering human intent from minimally instrumented physical substrates. The next research line asks a related but distinct question: what can be recovered about social and developmental processes from minimally instrumented observation of naturalistic human interaction and how should behavior be represented when the signal of interest is not what one person does, but what two people do together?
Conversational Head Movement: Interpretable Modeling of Social Dynamics
Research question
In my postdoctoral work at the Center for Autism Research, I used computer vision and machine learning to study head movement during short, naturalistic face-to-face conversations captured with a custom dual-camera system (BioSensor). A central design decision throughout this work was to treat head movement not as a coarse kinematic summary, but as a structured temporal signal whose meaning depends on social context.
I applied the same representation framework to two questions: how head-movement patterns vary with age across typical development, and how they differ between autistic and neurotypical adults. Through both studies, the goal was not only prediction, but localizing which temporal movement features carry developmentally or clinically relevant information.
An important part of the work is its observational footprint. The BioSensor setup used two synchronized cameras and a short conversation, with the system designed to minimize intrusiveness during natural interaction. That made it possible to capture naturalistic interaction without substantially altering it.


Naturalistic but instrumented. A custom dual-camera (BioSensor) captured synchronized conversational video from both partners while minimizing interference with face-to-face interaction. Left: conversation setting with a participant and confederate. Right: BioSensor close-up. From McDonald et al. (ICMI Companion). Figures from Center for Autism Research, Children’s Hospital of Philadelphia.
Pipeline architecture: temporal pattern encoding and feature construction
The computational pipeline, shared by both studies, uses a bag-of-words representation over short temporal windows of head-angle signals. Head pose was extracted from video to produce continuous signals for yaw, pitch, and roll, along with their framewise derivatives, yielding six signal streams per participant. Each stream was segmented into overlapping windows, z-scored to capture shape rather than raw magnitude, and assigned to clusters learned by a K-means model trained per angle, producing a vocabulary of prototypical movement patterns.
From there, I constructed two complementary feature types. Monadic features quantify how often a participant’s windows are assigned to each cluster, yielding a bag-of-words histogram over movement patterns. Dyadic features encode something qualitatively different: not just what each person does, but what both people do at the same time. For each participant–confederate signal pair, I computed a co-occurrence matrix whose cells count simultaneous cluster assignments. Extending this across angles and cross-direction pairs yields a feature space that explicitly represents interpersonal coordination rather than treating each speaker’s behavior as independent.
Across both studies, the computational logic is the same: convert short temporal patterns into an interpretable vocabulary, then ask whether distributions or co-occurrences of those patterns carry meaningful social signal.
Developmental findings: head-movement patterns as age probes
In Head Movement Patterns during Face-to-Face Conversations Vary with Age (ICMI Companion 2022), I applied this framework to 79 neurotypical participants aged 5.5–48 and compared monadic and dyadic features for classifying participants as younger or older than 12 years. Dyadic features achieved 78.6% accuracy versus 71.4% for monadic features, and a regression analysis using dyadic features yielded r = 0.42 (p = 0.0001) between predicted and chronological age.
The dyadic advantage matters because it suggests that developmental signal is not confined to the participant alone. Age appears to influence not only a person’s own head movements, but also how their conversation partner behaves in response. That makes the signal interactional rather than purely individual.
The relationship between thresholded classification and continuous-age regression is also informative. Classification was more robust than exact age prediction, which is consistent with the interpretation that nonverbal communication stabilizes across development, after which within-age variation dominates finer-grained continuous prediction.
Feature analysis made these results interpretable. In the monadic setting, the most informative features occurred more often in the younger group, suggesting more frequent or more varied head-movement patterns. In the dyadic setting, many of the most informative features came from the confederate rather than the participant, indicating that developmental signal is partly carried by the interaction partner’s behavioral accommodation.
Autism classification and clinical nuance
In Predicting Autism from Head Movement Patterns during Naturalistic Social Interactions (ICMHI 2023), I applied the same framework to conversations involving 15 autistic and 27 neurotypical adults. Dyadic features achieved 80.0% accuracy versus 69.2% for monadic features, reinforcing the methodological point that social communication differences are better captured in the interaction than in isolated behavior.
At the same time, the full performance breakdown matters. The dyadic classifier showed high specificity (93.3%) but substantially lower sensitivity (55.9%), making it considerably more reliable at identifying neurotypical individuals than autistic ones. The paper is explicit that the model is not intended for diagnostic purposes: its contribution is a scalable computational tool for studying subtle social-communication differences, not a clinical screening instrument.
A negative result is also useful in this context: simply concatenating monadic and dyadic features did not improve over dyadic features alone. That points to an open modeling question about how to integrate individual and relational behavioral signals without diluting the contribution of the lower-dimensional monadic representation.
Feature importance and interpretability
A common goal across both studies was to surface which movement patterns mattered, rather than treating the model as a black box. In the developmental paper, I extracted the most informative classifier features and visualized the corresponding cluster-centered movement patterns, making it possible to interpret which angles, directions, and speaker roles contributed most strongly to age-group classification.
In the autism paper, feature-weight analysis showed that movement magnitude was generally more influential than velocity, suggesting that the shape of how a person moves their head in response to a conversation partner may be more informative than movement speed alone. Among the three angles, pitch and yaw contributed more strongly than roll. Those results connect naturally to socially meaningful cues: pitch movements such as nodding can convey agreement, attentiveness, or contemplation, while yaw movements can reflect disagreement, reorientation, or shifts in attention.
The current representation also points to natural extensions. Angles are modeled independently, even though conversational head movement often involves coordinated motion across multiple axes. Likewise, the bag-of-words/co-occurrence representation captures time as a distribution over short temporal patterns rather than as a full trajectory. Both were reasonable choices for interpretability and tractability, but both suggest clear directions for richer future representations.
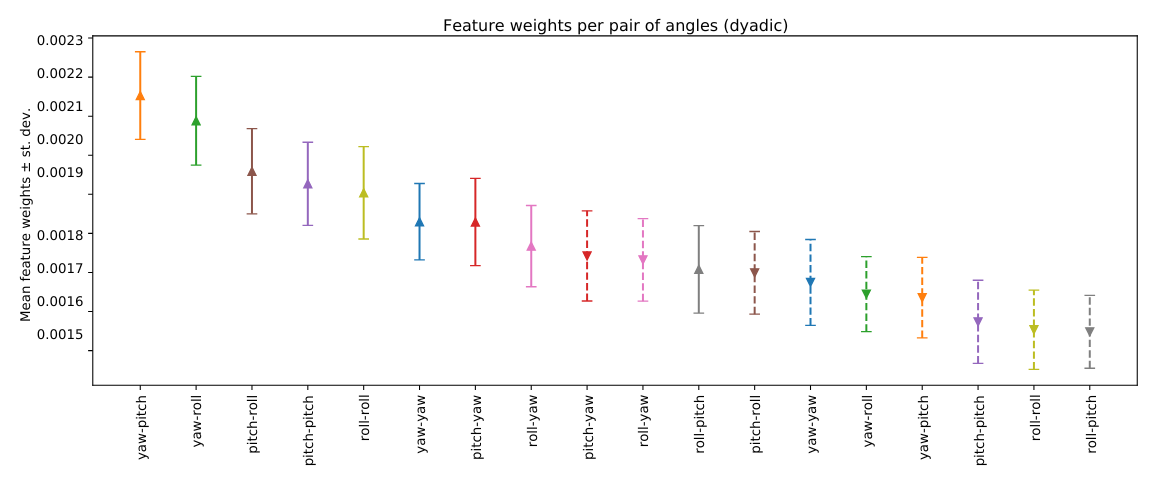
Dyadic feature importance across head-movement types. Mean and variance of SVM feature weights for dyadic features show that movement magnitude is generally more informative than velocity, and that pitch- and yaw-based relationships contribute more strongly than roll to autism classification. Adapted from McDonald et al. (ICMHI 2023).
Why this line of work matters
This project sits at the intersection of sequential modeling, computer vision, and computational behavior analysis. The most interesting ML question this work makes precise is not simply whether a classifier can separate groups, but how to represent relational behavior — what two people do in coordination over time — in a way that remains interpretable, data-efficient, and usable in naturalistic settings.
The bag-of-words plus co-occurrence construction is one tractable answer to that problem. It makes interpersonal structure explicit, supports feature-level interpretation, and works with a relatively minimal sensing setup. More broadly, the work shows that meaningful developmental and clinical signal can be recovered from unobtrusive social observation when the representation is designed around the structure of the interaction itself.
Physiological Signal Modeling and the Origins of BioHCI
My earlier work on physiological signals, especially fNIRS, helped establish the methodological foundations that later evolved into BioHCI. What mattered most in this line of work was not only applying machine learning to biosignals, but developing a principled approach to representing noisy, human-generated time series in a way that supports valid evaluation, reusable experimentation, and comparison across studies.
In User Identification from fNIRS Data Using Deep Learning, I studied whether resting-state fNIRS contains enough stable individual structure to support identification. Using data from 30 subjects, I constructed windowed statistical features over oxy-hemoglobin, deoxy-hemoglobin, their sum, and their difference, after channel selection, filtering, and normalization, and then trained a multilayer perceptron for classification. The best-performing configuration achieved 63% accuracy, compared with 3.3% chance, showing that even relatively noisy physiological data can contain meaningful subject-specific structure when represented carefully. The resting state context is significant: the brain signature sufficient to identify an individual was present without any task engagement, suggesting stable subject-specific structure in the signal itself rather than in task-induced responses. A secondary finding reinforced the importance of temporal resolution: accuracy degraded consistently as window size increased from 1 second to 90 seconds, indicating that the subject-specific signal was more recoverable at finer temporal scales. That result highlighted the importance of temporal granularity, a theme that continued in later BioHCI design.
This project already exhibits themes that continue throughout later work: representation before prediction, careful handling of noisy multi-channel signals, and attention to how evaluation design shapes what a model is actually learning. It also raised an issue that remains important: if stable individual structure can be recovered from brain data even at rest, these systems carry implications not only for biometrics and authentication, but also for privacy and data governance.
This work fed into the broader BioHCI framework described on the Systems page — a modular, subject-centered approach to human-generated signal analysis across sensing modalities. The methodological stance it reflects is simple: human-generated signals, whether physiological, behavioral, or sensorimotor, benefit from reusable abstractions for preprocessing, representation, and evaluation rather than being treated as isolated one-off modeling problems.
Research Outlook
Looking forward, I am interested in how representation learning can move beyond single-signal settings toward multimodal, relational models of real-world behavior. Across my work so far, meaningful structure has rarely resided in one variable alone: it emerges across channels, across time, across sensing modalities, and across interacting people. One direction I would especially like to pursue is how to integrate multiple sources of signal — including individual and relational behavioral structure — without losing the interpretability or specificity of each.
A second major direction is learning under distribution shift. My work has already touched this problem through cross-subject evaluation, zero-calibration inference, robustness to physical deformation and environmental interference, and modeling in naturalistic rather than tightly controlled settings. I am interested in pushing further on the question of what kinds of representations remain stable when real-world conditions depart from the assumptions of the training distribution.
At the same time, I want to continue exploring learning from sparse signals and minimal hardware. A through-line in my research has been to ask how far computational modeling can extend the capabilities of limited sensing substrates rather than relying on denser instrumentation. Beyond efficiency, I find this compelling as a human-centered design principle: the most successful technologies are often the ones that become less obtrusive, less demanding, and more effectively invisible to the people who use them.
Together, these directions define the research program I want to keep building: multimodal learning, structured and relational representations, robustness under shift, and low-observability inference for systems that work in the background of real human activity rather than interrupting it.